


Data-driven work calls for interaction among many components. foryouandyourcustomers would like to present two approaches that we often implement with our clients.
Note: The original article was published by Dr. Kilian Semmelmann.
Being a data-driven company is increasingly becoming the objective of many enterprises. But which aspects have to be taken into account on the path to data-based work?
The future belongs to data.
That’s why the only companies that will see success in the long term are those which collect, process, store and analyse strategic data. Data is the basis for optimisation, innovation and decisions in any organisation with modern and sustainable working practices. Only those enterprises that base their work on data – ‘data-driven companies’ – will be successful in the volatile, cut-throat corporate world of the future.
But what does working with data mean, exactly? Which components does an organisation need in order to use data efficiently and sustainably? And how does one go about becoming a data-driven company? We aim to answer these questions in this article and show how every company should act in order to secure their future success as well.
The data-driven company needs pyramid was developed by foryouandyourcustomers as a visual aid for illustrating the interdependency of the individual themes.
Pyramid of needs

Many companies equate ‘data driven’ with the use of artificial intelligence. Following this logic, an organisation may spend an extraordinary amount of money on data scientists as the solution for ensuring that the business is fit for the future. But soon the first problems arise: the data scientists either do not know which use cases are useful in the company or, when they want to move forward with implementation, they quickly run up against their limits in terms of data availability, infrastructure or quality.
These problems are the consequence of an unstructured approach to data. Instead of defining a clear strategic objective, the company simply crosses its fingers and hopes that software or individuals will come up with miracles out of thin air. But just as this approach does not work in other business areas, it also does not work in data science. The practical, targeted use of date calls for competency in a wide range of subjects.
To structure this approach, we have developed a needs pyramid for the data-driven company, which clearly illustrates the interdependency of the individual themes. In the following sections, we want to present all of the components of a data-driven company, starting with the basics – a solid, strategic look at the topic and a data-based culture – and moving on to competency through data acquisition, infrastructure and comprehensive governance, before finishing with effective, innovative application using modern approaches such as machine learning.
Data-based work is a question of culture
In the big picture, choosing data-based work is a cultural decision. Organic growth through small individual initiatives is possible, but in many cases leads to very low efficiency and frustration because the tools are seldom sufficiently available and the results are therefore not overwhelmingly convincing.
For this reason, we consider the basis of a data-driven company to be a clear decision to want to be a data-driven company in the first place and the implementation of this decision in a consistent approach within the corporate culture, organisation and customer orientation.
Only once you understand the benefits of data, of what data makes possible, do you have a real objective to aim for. This must also be reflected in the organisation: clear assignments of responsibility and appropriate expertise are combined to form a clear perspective, firmly anchoring this topic in the company.
By identifying clear use cases, you can identify and quantity the added value for the organisation. Last but not least, of course, you need the resources: support directly from the company’s executive management is the only way for a company to progress in terms of utilising data.
Together, this combination of strategy, use cases and organisation form the basis for every initiative in a data-driven company.
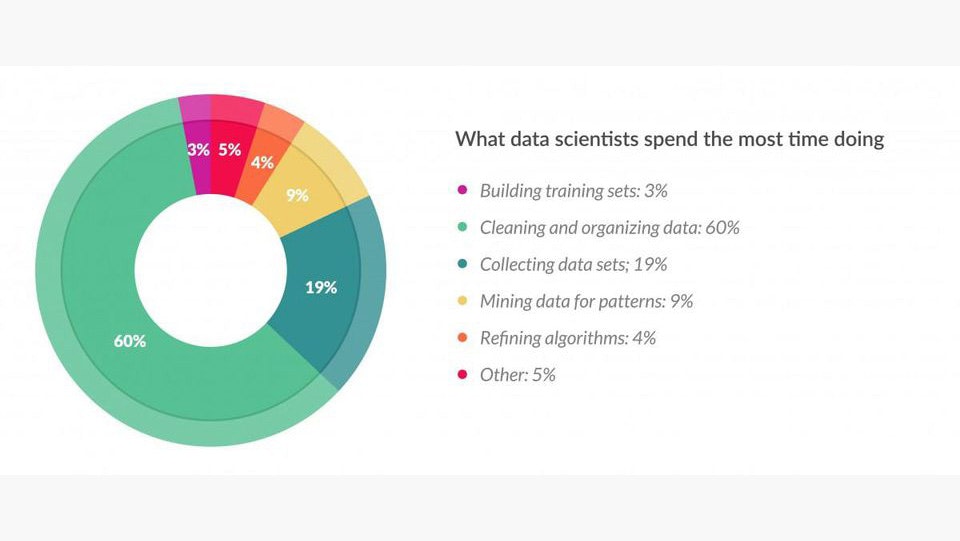
What data scientists spend the most time doing (according to www.forbes.com, download on 17th of June 2020)


No success without a foundation: data acquisition, infrastructure and data governance
‘Data scientists spend 80% of their time gathering and cleaning data.’ This quote or something similar is often used to show how data scientists really spend their working time. The humorous connotation of that aside, this quote also reveals the basic underlying problem when scaled up: there is hardly any company in which data scientists can work efficiently.
The problems mostly lie in the availability of data, the necessary infrastructure and the management of data, also known as data governance. Each of these aspects helps make efficient, sustainable work with data possible – or not, as the case may be. Together they form a sort of toolbox, without which any initiative becomes exponentially more complicated or of lower quality.
The competency of the company using systems, infrastructure, data acquisition and data governance is central to being able to work in a data-driven way.
The objective: generate insights, improve company processes and foster innovation.
The use of data can be roughly divided into three categories. The main objectives are to generate insights, improve processes and foster innovation.
The first of these encompasses everything that converts data into information or ideally, knowledge and insights, ranging from simple representative displays like graphical visualisation and dashboards to advanced deep learning algorithms. No matter what form these insights take, the aim is always to increase understanding of processes, customers and products and ideally improve them directly.
The aim of improving processes is to increase operational efficiency through automation and machine learning. The range of applications is very broad: it can entail both the creation of a simple infrastructure for delivering data and the embedding of machine learning models in the channel landscape. This part of data utilisation does not stop at insights, but instead uses data proactively within the company.
The third aspect is data-based innovation. Existing data, data acquisition, sleek analysis and/or deployment of artificial intelligence can be used to develop new products or even business models. This allows companies to structure themselves in layers and pursue the modern zeitgeist of personalised products.
Together both analysis and use of data are central to the optimisation of processes, the innovative further development of the company and also the decision-making process in a modern, overstimulated world.
Conclusion
It is clear that data-driven work cannot be reduced to a single aspect or solution. It calls for in-depth, detailed interaction among many components in order for a company to use data in an efficient and sustainable way.
The first and most important step towards data-driven work has already been taken by reading this article: you should now understand the scope of the topic and know what areas need to be taken into account. The next step now is to transition from knowing to doing, in order to initiate change and be competitive even in future.
So where do you start? Practical recommendations
Obviously there is much to be done. But where do you start? We want to break down this information into very practical pieces and present two approaches that we often implement with our clients.
The needs pyramid is fundamental to understand the subject matter and know where your own company is currently at. To evaluate these points, we use our own developed method, which we call the Data Readiness Assessment.
Data Readiness Assessment

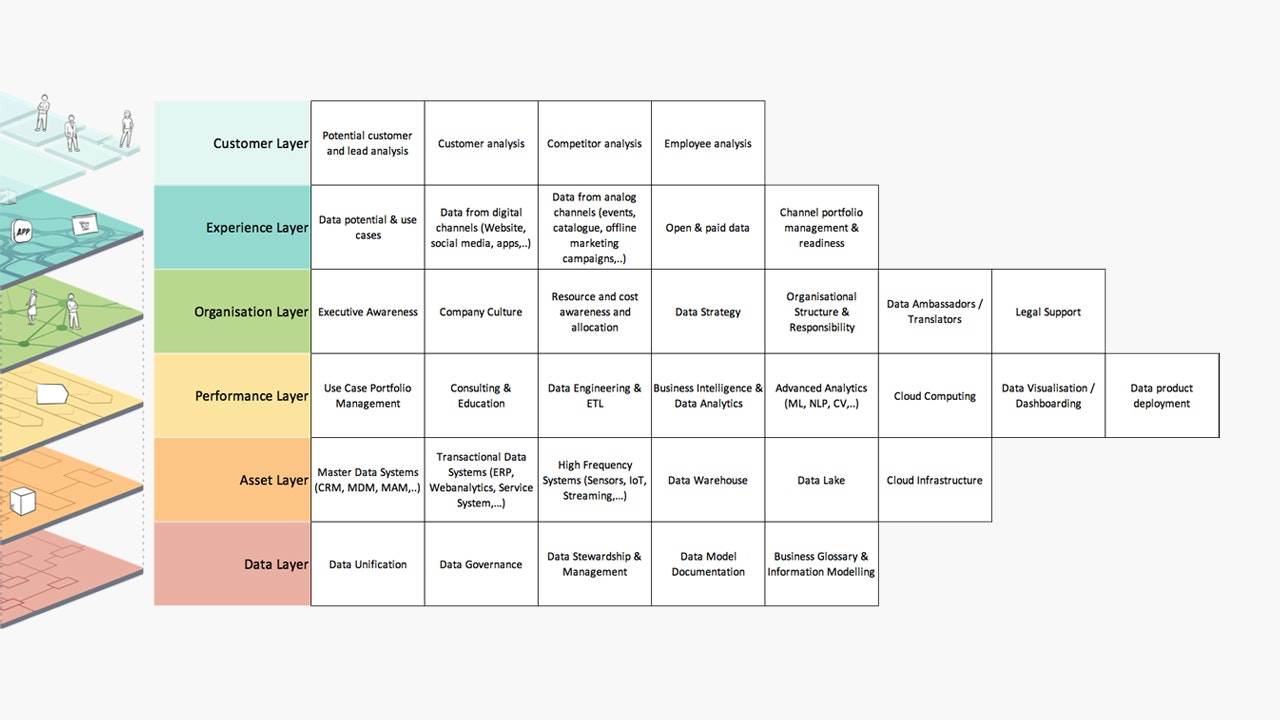
According to the needs pyramid, we think it is fundamental to understand the subject matter and know where your own company is currently at. To evaluate these points, we use our own developed method, which we call the Data Readiness Assessment. This very simple ‘actual’ analysis requires very little expense and is used to strategically evaluate where an organisation is at as well as identity specific approaches that could be used as next steps. With the help of over 30 subject areas related to the concept of a data-driven company, we investigate the status quo and degree of maturity of the company in order to introduce subsequent steps.
In contrast to this holistic, strategic approach are what are known as proofs of concept (POCs). POCs allow us to foster understanding and enthusiasm for the data-driven company and evaluate feasibility and success at the same time. In many organisations it makes sense to use this sort of ��‘firestarter’ to ignite the interest of the company in the topic and generate more enthusiasm to continue. Proofs of concept can take many forms. There are many different approaches, from a data pipeline that automates a process and classic analysis and tracking concepts, to sophisticated solutions using artificial intelligence.
Whether you prefer one of these methods or a different approach, at foryouandyourcustomers, data is considered fundamental no matter what. In our view, you can only be successful if you establish a holistic, comprehensive picture of how data is utilised in your organisation.
We would be pleased to hear feedback or start a dialogue with you about what the right approach for your company and your customers is.
If you are interested please contact us and send an eMail to Jens Plattfaut.


